在摊还分析中,我们求数据结构的一个操作序列中所执行的所有操作的平均时间,来评价操作的代价。这样,我们就可以说明一个操作的平均代价是很低的,即使序列中某个单一操作的代价很高。摊还分析不同于平均情况分析,它并不涉及概率,它可以保证最坏情况下每个操作的平均性能。
本章介绍三种摊还分析方法:
- 聚合分析
- 核算法
- 势能法
首先我们先看两个小问题
栈操作
对传统的栈操作 MULTIPOP(S, k) 扩展,伪代码如下,相当于做 k 次 POP(S)
MULTIPOP(S, k)
1 while not STACK-EMPTY(S) and k > 0
2 POP(S)
3 k = k - 1如果在一个包含 s 个对象的栈上做 MULTIPOP(S, k) 操作,POP 的次数为 min(s, k)。
我们来分析一个由 PUSH/POP/MULTIPOP 组成的操作序列在一个空栈上的执行情况。MULTIPOP 的最坏代价为
二进制计数器递增
A[0..k-1] 作为计数器。当计数器保存二级制数 A[0] 中,最高位保存在 A[k-1] 中,因此INCREMENT 的伪代码如下:
INCREMENT(A)
1 i = 0
2 while i < A.length and A[i] == 1
3 A[i] = 0
4 i = i + 1
5 if i < A.length
6 A[i] = 1可以想象,最坏情况当 INCREMENT 操作要做
从上两个问题,我们都根据一个操作最坏情况的时间消耗推测,整个操作序列的时间消耗,显然不是一个确界。下面我们通过三种摊还分析方法来分析这两个问题中每个操作的平均代价(摊还代价)。
聚合分析
聚合分析——确定
栈操作:
虽然单独的 MULTIPOP 操作可能代价很高,但在一个空栈上实行 POP 和 MULTIPOP 操作的总消耗最多为 push 进去数据,POP 和 MULTIPOP 才会有消耗,而且 PUSH 操作每次只能 push 一个数据进来。所以
二进制计数器递增:
下图展示了二进制计数器从 0 递增到 16 的过程,阴影部分表示递增后需要翻转的位。我们可以发现 A[0]每次递增时都发生翻转,A[1] 每两次递增发生一次翻转,A[2] 每四次递增发生一次翻转,以此类推第 INCREMENT 操作后,第
执行 n 次 INCREMENT 操作产生的总翻转次数为:
所以,INCREMENT 操作的最坏情况用时为 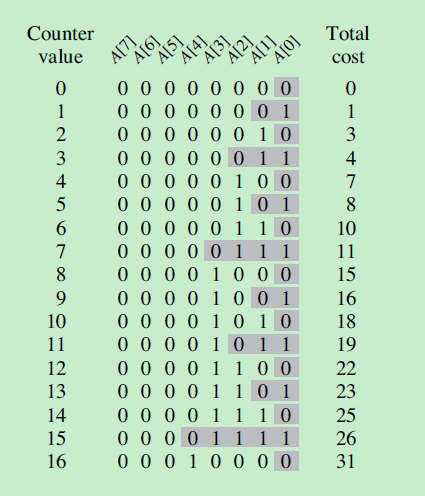
核算法
核算法——对不同的操作赋予不同的费用(可以大于或者小于实际的代价,但不能为负值),称其为摊还代价。当一个操作摊还代价大于实际代价时,我们将差额存起来,称其为信用/存款。后续操作如果有摊还代价小于实际代价时,我们将之前存的信用拿出一部分来抵消这里的差值。如果用
信用总能刚好抵债或者有剩余,从而使得总的摊还代价为总实际代价的上界。
栈操作:
栈操作的实际代价如下:
PUSH 1
POP 1
MULTIPOP min(k, s)我们将栈操作的摊还代价设置为:
PUSH 2
POP 0
MULTIPOP 0每次 PUSH 操作支付 1 的实际代价,剩下的 1 存起来。存起来的钱和堆栈里的数据量相同,而 POP 或 MULTIPOP 操作的实际代价为要 pop 的数据量,所以存款总能保证大于等于零。
每个操作的摊还代价都是常数,所以总的摊还代价为
二进制计数器递增:
将 INCREMENT 中的操作分为置位操作(第 6 行,0->1)和复位操作(while 循环中的操作,1->0)。令置位操作的摊还代价为 2,复位操作的摊还代价为 0。每次置位操作可以多出 1 存起来(存起来的钱和计数器中 1 的个数相同),复位操作需要预支存款,但复位操作只有当某一位是 1 的时候才会执行,由于计数器中 1 的个数永远不会为负,所以存款总能保证大于等于零。
每个操作的摊还代价都是常数,所以总的摊还代价为 O(n)。
势能法
势能法将数据结构和势能关联起来——对一个初始化数据结构
即,每个操作的摊还代价为实际代价加上操作引起的势变化。所以总摊还代价为:
根据公式 1 可以得到每个步骤的摊还代价,从而算出总的摊还代价,然后根据公式 2 可以得出总实际代价的上界/下界(
| `````````````` | 核算法 | 势能法 |
|---|---|---|
| 摊还代价 | 猜想/推测得到 | 通过实际代价加势能变化得到 |
| 思想 | 较为简单 | 较为抽象 |
| 难点 | 需要证明存款足以抵债 | 需要考虑一个好的势函数 |
| 优势 | 考虑起来较为容易 | 应用范围广,适用的场景更多 |
| 联系 | 核算法的存款往往能和势能法的势函数相对应 | 势能法中计算摊还代价时,当势差为正数时相当于将势差作为存款存起来,当势差为负数时相当于要用存款中拿出部分来抵债,所以两种方法的内涵是一致的 |
栈操作:
将势函数定义为当前栈中的数据量。PUSH 操作会压入一个数据,所以势差为 PUSH 操作的摊还代价为 POP/MULTIPOP 操作会弹出 POP/MULTIPOP 操作的摊还代价为
栈每个操作的摊还代价都是
二进制计数器递增:
将势函数定义为计数器中
假设第
再来考虑摊还代价,如果
如果
所以总摊还代价的上界为
势能法的还有个优势就是,我们可以简单的得出当初始状态不是
所以只要
动态表
11 章介绍了散列表,我们知道散列表的大小和数据量应该是线性相关的,数据太稀疏会浪费空间,数据太稠密会浪费时间。当我们不知道会有多少数据插入时,就没办法确定散列表的大小,所以要引进动态表。
表扩张——当插入数据时发现散列表的装载因子为
表收缩——当删除数据时发现散列包的装载因子小于某个值,对表进行收缩,与表的扩张类似,比如收缩为原来表大小的一半,首先删除这个数据并创建一般大小的新表,将原来散列表中的数据插入新创建的表中,然后把老的表析构。
表收缩时判断的装载因子的选择很重要,如果表扩张选择的两倍大小,而表收缩是选择装载因子为二分之一,这时如果在表扩张后立马删除数据,又反复的插入,删除数据,这样会导致表大小的震荡。这种情况下时间机器浪费时间。
所以我们通常可以选择该装载因子为四分之一来避免这个问题。
无论是表扩张还是表收缩,我们都可以用平摊分析来证明动态表的插入和删除操作的平均代价还是